在從事資料科學工作的時候,經常會遇到為具體問題選擇最合适算法的問題。雖然有很多有關機器學習算法的文章詳細介紹了相關的算法,但要做出最合适的選擇依然非常困難。
在這篇文章中,我将對一些基本概念給出簡要的介紹,對不同任務中使用不同類型的機器學習算法給出一點建議。在文章的最後,我将對這些算法進行總結。
首先,你應該能區分以下四種機器學習任務:
監督學習
無監督學習
半監督學習
強化學習
監督學習是從标記的訓練資料中推斷出某個功能。通過拟合标注的訓練集,找到最優的模型參數來預測其他對象(測試集)上的未知标簽。如果标簽是一個實數,我們稱之為回歸。如果标簽來自有限數量的值,這些值是無序的,那麼稱之為分類。
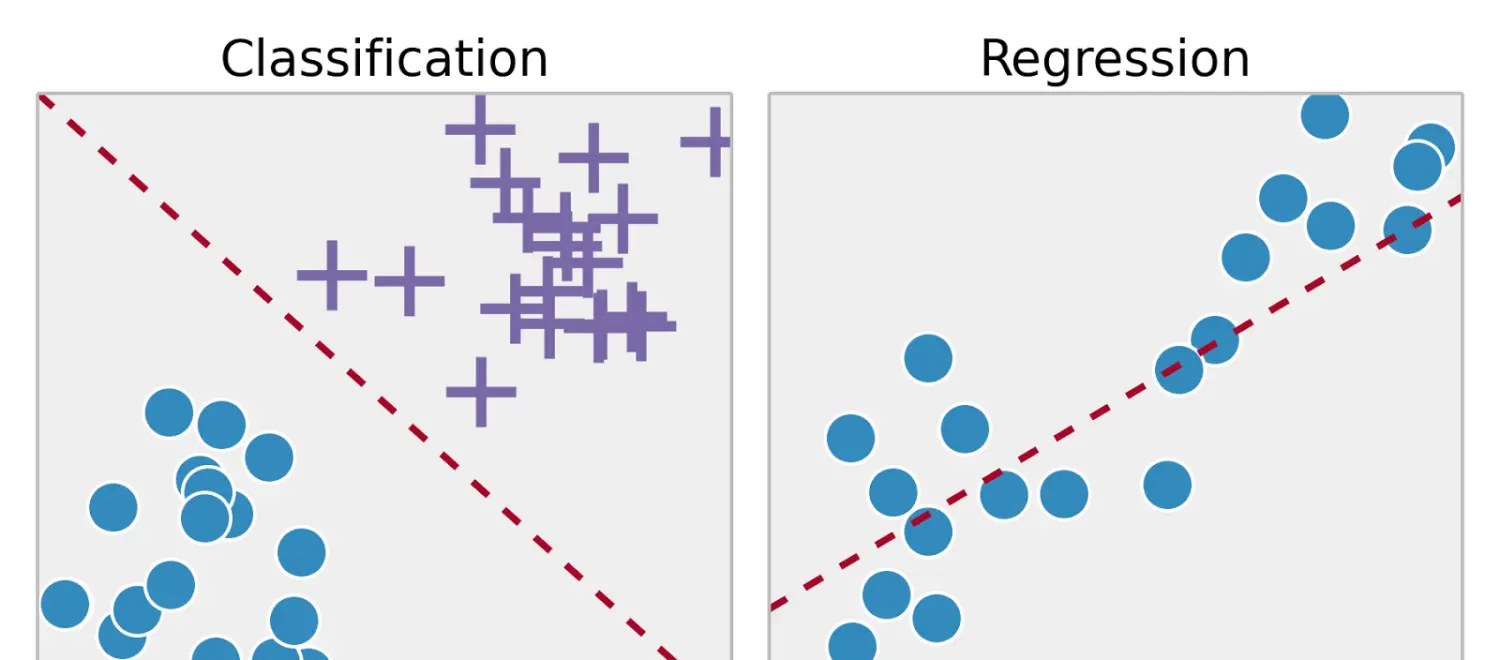
在無監督學習中,我們對于物體知道的資訊比較少,特别是訓練集沒有做過标記。那現在的目标是什麼呢?觀察對象之間的相似性,并将它們劃分到不同的群組中。某些對象可能與其他群組中的對象都有很大的差別,那麼我們就認為這些對象是異常的。

半監督學習包括了前面描述的兩個問題:同時使用标記和未标記的資料。對于那些無法标注所有資料的人來說,這是一個很好的方法。該方法能夠顯著提高準确性,因為在使用訓練集中未标記資料的同時,還能使用少量帶有标記的資料。
強化學習跟上面提到的方法不太一樣,因為在這裡并沒有标記或未标記的資料集。強化學習涉及到軟體代理應該如何在某些環境中采取行動來最大化累積獎勵。
想象一下,你是一個在陌生環境中的機器人,你可以執行一些動作,并從中獲得獎勵。在每執行一個動作之後,你的行為會變得越來越複雜越來越聰明,也就是說 ,你正在訓練自己在執行每一個動作之後讓自己表現得更為有效。在生物學中,這被稱為适應自然環境。
現在,我們對機器學習的類型有了一定的了解,下面,我們來看一下最流行的算法及其在現實生活中的應用。
在實踐中,使用梯度下降來進行優化則更為容易,計算上更有效率。盡管這個算法很簡單,但是在存在成千上萬個特征的時候,這個方法依然能夠表現良好。更複雜的算法可能會遇到過拟合特征或者是沒有足夠大的資料集的問題,而線性回歸則是一個不錯的選擇。
為了防止過拟合,可使用像lasso和ridge這樣的規則化技術。其主要思路是分别把權重總和以及權重平方的總和加到損失函數中。
邏輯回歸執行的是二進制分類,是以輸出的标簽是二進制的。給定輸入特征向量x,定義P(y=1|x)為輸出y等于1時的條件機率。系數w是模型要學習的權重。
由于該算法需要計算每個類别的歸屬機率,是以應該考慮機率與0或1的差異程度,并像線上性回歸中一樣對所有對象取平均值。這種損失函數是交叉熵的平均值:
邏輯回歸有什麼好處呢?它采用了線性組合的特征,并對其應用非線性函數(sigmoid),是以它是一個非常小的神經網絡執行個體!
另一個比較流行、并且容易了解的算法是決策樹。它的圖形能讓你看到你自己的想法,它的引擎有一個系統的、有記錄的思考過程。
這個算法很簡單。在每個節點中,我們選擇所有特征和所有可能的分割點之間的最佳分割。選擇每個分割以最大化某些功能。在分類樹中使用交叉熵和基尼指數。在回歸樹中,最小化該區域中的點的目标值的預測變量與配置設定給它的點之間的平方誤差的總和。
算法會在每個節點上遞歸地完成這個過程,直到滿足停止條件為止。
有的時候你并不知道标簽,而目标是根據對象的特征來配置設定标簽。這被稱為集聚化任務。
假設要把所有的資料對象分成k個簇,則需要從資料中随機選擇k個點,并将它們命名為簇的中心。其他對象的簇由最近的簇中心定義。然後,聚類的中心會被轉換并重複該過程直到收斂。
雖然這個技術非常不錯,但它仍然有一些缺點。首先,我們并不知道簇的數量。其次,結果依賴開始時随機選擇的那個點,算法無法保證我們能夠實作功能的全局最小值。
昨晚或者最近的幾個小時裡你有沒有在準備考試?你無法記住所有的資訊,但是想要在可用的時間内最大限度地記住資訊,例如,首先學習考試中經常出現的定理等等。
主成分分析基于類似的思想。該算法提供了降維的功能。有時,你有很多的特征,并且彼此之間強相關,模型可以很容易地适應大量的資料。然後,你可以應用PCA。
你應該計算某些向量上的投影,以使資料的方差最大化,并盡可能少地丢失資訊。而這些向量是來自資料集特征的相關矩陣的特征向量。
算法的内容現在已經很清楚了:
計算特征列的相關矩陣,找出該矩陣的特征向量。
将這些多元向量計算出來,并計算所有特征的投影。
新特征是投影中的坐标,其數量取決于投影的特征向量的數量。
在上文講到邏輯回歸的時候,就已經提到了神經網絡。在一些具體的任務中,有很多不同的體系結構都非常有價值。而神經網絡更多的時候是一系列的層或元件,它們之間存線上性連接配接并遵循非線性。
如果你正在處理圖像,那麼卷積深度神經網絡能展現出不錯的結果。而非線性則通過卷積層和彙聚層表現出來,它能夠捕捉圖像的特征。
我希望能向大家解釋最常用的機器學習算法,并就針對具體問題如何選擇機器學習算法提供建議。為了能讓你更輕松的掌握這些内容,我準備了下面這個總結。
線性回歸和線性分類器。盡管看起來簡單,但當其他算法在大量特征上遇到過拟合的問題時,它的優勢就表現出來了。
Logistic回歸是最簡單的非線性分類器,具有二進制分類的參數和非線性函數(S形)的線性組合。
決策樹通常與人類的決策過程相似,并且易于解釋。但它們最常用于随機森林或梯度增強這樣的組合中。
K-means是一個更原始、但又非常容易了解的算法。
PCA是降低資訊損失最少的特征空間次元的絕佳選擇。
神經網絡是機器學習算法的新武器,可以應用于許多任務,但其訓練的計算複雜度相當大。
文章原标題《Machine Learning Algorithms: Which One to Choose for Your Problem》,作者: Daniil Korbut,譯者:夏天,審校:主題曲。