為什麼需要Kylin?
Hadoop幫助我們解決了海量資料的存儲。
早期使用Hadoop的MapReduce計算模型,太慢了,隻能做離線計算,無法做實時計算與疊代式計算。
Spark應運而生,并帶動了Scala語言的發展,Spark的MapReduce計算模型比Hadoop的MapReduce計算模型性能提升了數十倍。
在現今的企業發展中,資料的增量是每日以百MB、G為機關的增長,面對如此之大的規模性資料增長,及營運成本、硬體成本、響應速度等各方面影響下,Spark也夠嗆。
在這種情況下,企業查詢一般分為即席查詢和定制查詢。
即席查詢:Hive、SparkSQL等OLAP引擎,雖然在一定程度上降低了資料分析的難度,但他們隻用于即席查詢的場景,優點就是使用者根據自己的需求,自定義、靈活的選擇查詢條件,與普通查詢最大的差別在于普通查詢時根據應用定制的開發查詢條件,但随着資料量和計算複雜度的增長,響應資料無法得到保證。
實時查詢:多數情況下是對使用者的操作做出實時反應,Hive等查詢引擎很難滿足實時查詢,一般隻能對資料庫中的資料進行提取計算,然後将結果存入MySQL等關系型資料庫,最後提供給使用者進行查詢,随着後面海量資料的遞增,這種方式的代價很大。
Kylin不同于大規模并行處理的Hive等架構,Kylin是預計算的模式,我們提前定義好查詢的次元,Kylin就會幫助我們進行計算,并将結果存儲到Hbase,當我們在去查詢海量資料和分析時,提供亞秒級傳回。
Kylin很明顯采用的是空間換時間的政策,先将定義好的各個字段進行交叉查詢,将這些查詢好的資料放到資料庫中,當我們去查詢時這個時候資料量也少了,如果查詢語句和預計算的語句是一樣的,那樣則可以直接傳回,是以Kylin查詢速度很快。
Apache Kylin(Extend OLAP Engine For Big Data)中文名為麒麟,是Hadoop生态圈的重要成員,是一個開源的分布式分析引擎,最初是由eBay開發的,提供了Hadoop之上的SQL查詢接口及多元分析(OLAP)功能,支援高并發處理TB至PB級别的大規模海量資料,能夠在亞秒級查詢巨大的Hive表。
Kylin在2014年10月在Github開源,2014年11月加入Apache,2015年11月成為頂級項目,也是第一個完全由中國團隊設計開發的Apache頂級項目,2016年3月Kylin核心開發成員成立了Kyligence公司來推動項目和社群的發展。
Cube可以說是Kylin的核心,Kylin就是通過建構Cube,進而達到亞秒級的海量資料搜尋。
在建構Cube前,要先進行資料倉庫的設計和架構,進而确定好要分析次元和名額(度量),根據定義好的次元和名額(度量)就可以建構Cube了。
Cube是對于一個給定的資料模型的所有次元進行組合、計算。
對于N個次元來說,組合的可能性共有2的N次方,對于每一種次元的組合,将名額(度量)做聚合計算。
其中每一種次元組合稱為Cubeid,一個Cubeid包含一種具體次元組合下所有名額的值。
如下圖,是一個四維的Cube建構過程。
假設有一個點上的銷售資料集,其中的次元包括時間、商品、地點、供應商四個次元,名額為銷售額,那麼所有次元的組合就有2的4次方,剛好對應下圖。
如果提前計算好,那麼在寫SQL連表操作時,一下子就出來結果了。
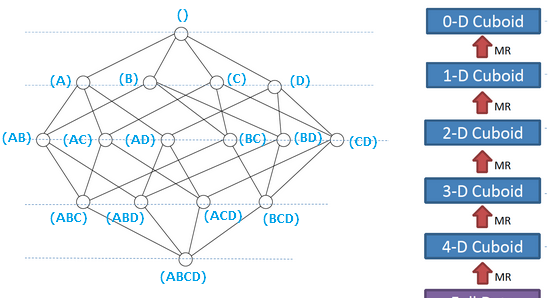
Kylin的核心思想是預計算,即對多元分析可能用到的名額(度量)進行計算,将計算好的結果儲存成Cube,供查詢時,直接通路,把高複雜度的聚合運算、多表連接配接等操作轉換成對預計算結果的查詢,這決定了Kylin能夠擁有很好的快速查詢和高并發的能力。
進而Kylin提供了一個稱為Layer Cubing的算法來建構Cube,這個算法是按照次元(Dimension)數量從大到小的順序,從Base Cuboid開始,依次給予上一層的結果進行再次聚合,每一層的計算都是一個單獨的MapReduce任務。
這裡面的Map和Reduce還是比較簡單的,Mapper以上一層Cuboid的結果作為輸入,由于Key是由各次元值拼接在一起,從其中找出要聚合的次元,去掉它的值成新的Key,并對Value進行操作,然後把新Key和Value輸出,進而對所有新Key進行排序,洗牌(Shuffle),再Reduce,Reduce的輸入是一組有相同Key的Value集合,對這些Value做聚合計算,再結合Key輸出就完成了一輪計算。
每一輪的計算都是一個MapReduce任務,而且是串行執行,一個N維的Cube,至少需要N次MapReduce Job。
Kylin是把MapReduce的計算結果最終儲存在HBase中,對于跨度查詢(年、季度、月等)Kylin是使用Cube的Data Segment分區存儲管了解決。
而HBase中每行記錄的RowKey由次元(Dimension)組成,Cuboid的名額會儲存在Column Family中映射為Value,為了減少存儲的代價,這裡會對次元和名額進行編碼。
查詢階段利用HBase列存儲的特性就可以保證Kylin有良好的快速響應和高并發。

Kylin支援多種資料源,預設的資料源是Hive。
Kylin采用預計算的方式,預設的預計算結果存儲引擎是HBase。
REST Server是一條面向應用程式開發的入口點,此類應用程式可以提供查詢、擷取結果、觸發Cube建構任務、擷取中繼資料及使用者權限等,還可以通過Restful接口實作SQL查詢。
當Cube準備就緒後,查詢引擎能夠擷取并解析使用者查詢的語句,并與其他元件互動,傳回使用者對應的結果。
将解析SQL生成的執行計劃轉為Cube緩存查詢,Cube通過預計算緩存在HBase中,使用者查詢時,利用router查詢算法和優化的HBase Coprocessor解決。
管理儲存在Kylin中的所有中繼資料,包括Cube中繼資料,其他的元件都是以此為基礎,Kylin的技術中繼資料和業務中繼資料都是存儲在HBase的。
處理并協調所有離線任務,包括Shell腳本、JavaApi、MapReduc任務等。
Kylin Cube建構分為三種,全量建構、增量建構、流式建構。
全量建構:每次都對Hive表進行全表建構,但這種建構方式在實際環境中并不常用,隻有在初始化時用的較多,因為大多數業務場景下,事實表的資料是不斷的增長的。
增量建構:使得Cube每次隻建構Hive表中新增的部分資料,而不是全部資料,是以降低了建構成本,Kylin将Cube分為多個Segment,每個Segment用起始時間和結束時間來辨別。
增量建構的方式解決了業務資料動态增長的問題,但是卻不能滿足分鐘級近實時傳回結果的需求,因為增量建構他們使用的是Hive作為資料量,Hive中的資料由ETL定時導入(如每天一次),資料的時效性對于資料價值的重要性不言而喻。
增量建構和全量建構的差別:
1.建立Model時需要制定Partition Date Column(分區日期資料列),用日期對Cube進行分割。
2.建立Cube時需要制定Partition Start Date,即Cube預設的第一個Segemnt的起始時間。
官方文檔:http://kylin.apache.org/docs20/tutorial/create_cube.html
http://kylin.apache.org/docs20/tutorial/cube_build_job.html
流式建構:為了解決資料實時增長的問題,流式建構使用Kafka作為資料源,建構引擎定時從Kafka中拉取資料進行建構,這個設計和Spark Streaming的定時微批次很類似,這個是在Kylin 1.6版本後存在的。
Kylin主要對外的接口是以SQL的形式提供的,SQL簡單易用的特性極大的降低了Kylin的學習成本。
不論是Hive、SparkSQL、還是Impala,它們的查詢時間都随着資料量的增長而線性增長,而Apache Kylin使用預計算技術打破這一點,Kylin在資料集規模上的局限性主要取決于次元的個數和基數(次元表内的資料量),而不是資料集的大小,是以Kylin能更好的支援海量資料集的查詢。
Kylin是采用預計算的技術,是以查詢速度非常快,因為複雜的連接配接、聚合等操作都在Cube的建構過程中已經完成了。
Apache Kylin同樣可以使用叢集部署方式進行水準擴充,但部署多個節點隻能提高Kylin處理查詢的能力,而不能提升它的預計算能力(算法)。
Kylin提供與BI工具整合的能力,如Tableau、PowerBI/Excel、MSTR、QlikSense、Hub、SuperSet等。
使用者能夠在Kylin裡為百億級以上資料集定義資料模型并建構立方體。
Kylin執行個體是無狀态的,運作時狀态(中繼資料)是存儲在HBase(由conf/kylin.properties中的kylin.metadata.url指定)中的metadata中,是以在表結構中共享統一個狀态(job狀态,Cube狀态等)。
每一個Kylin執行個體在conf/kylin.properties中都有一個Kylin.server.mode entry,指定運作時的模式。
job:在執行個體運作中job engine負責管理叢集中的jobs
query:隻運作query engine,負責接收和回應SQL查詢。
all:在執行個體中即運作job engine,也可以運作query engines。
注:預設情況下隻有一個執行個體可以運作job engine(all或job模式),其餘需要query模式,類似Master/Slave模式。