關注公衆号:大資料技術派,回複“資料”,領取1000G資料。 本文首發于我的個人部落格:Flink狀态管理
有狀态的計算是流處理架構要實作的重要功能,因為稍複雜的流處理場景都需要記錄狀态,然後在新流入資料的基礎上不斷更新狀态。下面的幾個場景都需要使用流處理的狀态功能:
資料流中的資料有重複,想對重複資料去重,需要記錄哪些資料已經流入過應用,當新資料流入時,根據已流入過的資料來判斷去重。
檢查輸入流是否符合某個特定的模式,需要将之前流入的元素以狀态的形式緩存下來。比如,判斷一個溫度傳感器資料流中的溫度是否在持續上升。
對一個時間視窗内的資料進行聚合分析,分析一個小時内某項名額的75分位或99分位的數值。
一個狀态更新和擷取的流程如下圖所示,一個算子子任務接收輸入流,擷取對應的狀态,根據新的計算結果更新狀态。一個簡單的例子是對一個時間視窗内輸入流的某個整數字段求和,那麼當算子子任務接收到新元素時,會擷取已經存儲在狀态中的數值,然後将目前輸入加到狀态上,并将狀态資料更新。

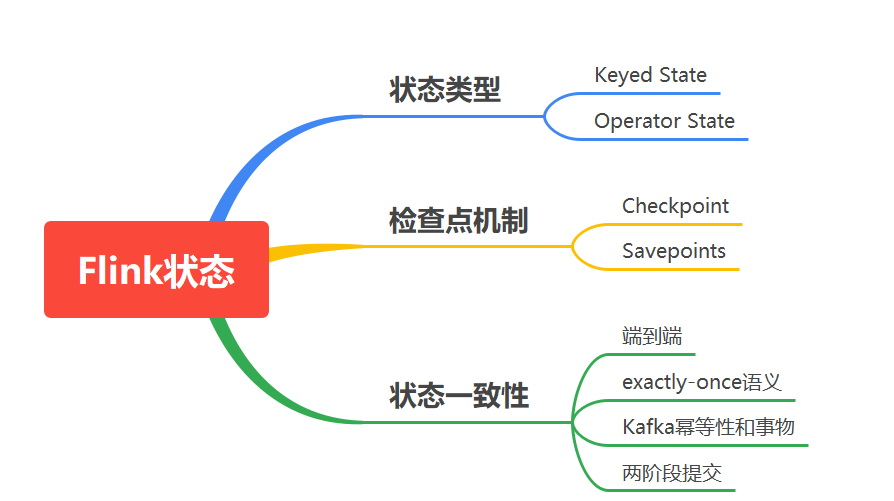
Flink有兩種基本類型的狀态:托管狀态(Managed State)和原生狀态(Raw State)。
兩者的差別:Managed State是由Flink管理的,Flink幫忙存儲、恢複和優化,Raw State是開發者自己管理的,需要自己序列化。
具體差別有:
從狀态管理的方式上來說,Managed State由Flink Runtime托管,狀态是自動存儲、自動恢複的,Flink在存儲管理和持久化上做了一些優化。當橫向伸縮,或者說修改Flink應用的并行度時,狀态也能自動重新分布到多個并行執行個體上。Raw State是使用者自定義的狀态。
從狀态的資料結構上來說,Managed State支援了一系列常見的資料結構,如ValueState、ListState、MapState等。Raw State隻支援位元組,任何上層資料結構需要序列化為位元組數組。使用時,需要使用者自己序列化,以非常底層的位元組數組形式存儲,Flink并不知道存儲的是什麼樣的資料結構。
從具體使用場景來說,絕大多數的算子都可以通過繼承Rich函數類或其他提供好的接口類,在裡面使用Managed State。Raw State是在已有算子和Managed State不夠用時,使用者自定義算子時使用。
對Managed State繼續細分,它又有兩種類型:Keyed State和Operator State。
為了自定義Flink的算子,可以重寫Rich Function接口類,比如RichFlatMapFunction。使用Keyed State時,通過重寫Rich Function接口類,在裡面建立和通路狀态。對于Operator State,還需進一步實作CheckpointedFunction接口。
Flink 為每個鍵值維護一個狀态執行個體,并将具有相同鍵的所有資料,都分區到同一個算子任務中,這個任務會維護和處理這個key對應的狀态。當任務處理一條資料時,它會自動将狀态的通路範圍限定為目前資料的key。是以,具有相同key的所有資料都會通路相同的狀态。
需要注意的是鍵控狀态隻能在 KeyedStream 上進行使用,可以通過 stream.keyBy(...) 來得到 KeyedStream 。
Flink 提供了以下資料格式來管理和存儲鍵控狀态 (Keyed State):
ValueState:存儲單值類型的狀态。可以使用 update(T) 進行更新,并通過 T value() 進行檢索。
ListState:存儲清單類型的狀态。可以使用 add(T) 或 addAll(List) 添加元素,update(T)進行更新;并通過 get() 獲得整個清單。
ReducingState:用于存儲經過 ReduceFunction 計算後的結果,使用 add(T) 增加元素。
AggregatingState:用于存儲經過 AggregatingState 計算後的結果,使用 add(IN) 添加元素。
FoldingState:已被辨別為廢棄,會在未來版本中移除,官方推薦使用 AggregatingState 代替。
MapState:維護 Map 類型的狀态,get擷取,put更新,contains判斷包含,remove移除元素。
Operator State可以用在所有算子上,每個算子子任務或者說每個算子執行個體共享一個狀态,流入這個算子子任務的資料可以通路和更新這個狀态。
算子狀态不能由相同或不同算子的另一個執行個體通路。
Flink為算子狀态提供三種基本資料結構:
ListState:存儲清單類型的狀态。
UnionListState:存儲清單類型的狀态,與 ListState 的差別在于:如果并行度發生變化,ListState 會将該算子的所有并發的狀态執行個體進行彙總,然後均分給新的 Task;而 UnionListState 隻是将所有并發的狀态執行個體彙總起來,具體的劃分行為則由使用者進行定義。
BroadcastState:用于廣播的算子狀态。如果一個算子有多項任務,而它的每項任務狀态又都相同,那麼這種特殊情況最适合應用廣播狀态。
假設此時不需要區分監控資料的類型,隻要有監控資料超過門檻值并達到指定的次數後,就進行報警:
狀态的橫向擴充問題主要是指修改Flink應用的并行度,确切的說,每個算子的并行執行個體數或算子子任務數發生了變化,應用需要關停或啟動一些算子子任務,某份在原來某個算子子任務上的狀态資料需要平滑更新到新的算子子任務上。
Flink的Checkpoint就是一個非常好的在各算子間遷移狀态資料的機制。算子的本地狀态将資料生成快照(snapshot),儲存到分布式存儲(如HDFS)上。橫向伸縮後,算子子任務個數變化,子任務重新開機,相應的狀态從分布式存儲上重建(restore)。
對于Keyed State和Operator State這兩種狀态,他們的橫向伸縮機制不太相同。由于每個Keyed State總是與某個Key相對應,當橫向伸縮時,Key總會被自動配置設定到某個算子子任務上,是以Keyed State會自動在多個并行子任務之間遷移。對于一個非KeyedStream,流入算子子任務的資料可能會随着并行度的改變而改變。如上圖所示,假如一個應用的并行度原來為2,那麼資料會被分成兩份并行地流入兩個算子子任務,每個算子子任務有一份自己的狀态,當并行度改為3時,資料流被拆成3支,或者并行度改為1,資料流合并為1支,此時狀态的存儲也相應發生了變化。對于橫向伸縮問題,Operator State有兩種狀态配置設定方式:一種是均勻配置設定,另一種是将所有狀态合并,再分發給每個執行個體上。
為了使 Flink 的狀态具有良好的容錯性,Flink 提供了檢查點機制 (CheckPoints) 。通過檢查點機制,Flink 定期在資料流上生成 checkpoint barrier ,當某個算子收到 barrier 時,即會基于目前狀态生成一份快照,然後再将該 barrier 傳遞到下遊算子,下遊算子接收到該 barrier 後,也基于目前狀态生成一份快照,依次傳遞直至到最後的 Sink 算子上。當出現異常後,Flink 就可以根據最近的一次的快照資料将所有算子恢複到先前的狀态。
預設情況下 checkpoint 是禁用的。通過調用 StreamExecutionEnvironment 的 enableCheckpointing(n) 來啟用 checkpoint,裡面的 n 是進行 checkpoint 的間隔,機關毫秒。
Checkpoint是Flink實作容錯機制最核心的功能,它能夠根據配置周期性地基于Stream中各個Operator的狀态來生成Snapshot,進而将這些狀态資料定期持久化存儲下來,當Flink程式一旦意外崩潰時,重新運作程式時可以有選擇地從這些Snapshot進行恢複,進而修正因為故障帶來的程式資料狀态中斷。這裡,我們簡單了解一下Flink Checkpoint機制,如官網下圖所示:
Checkpoint指定觸發生成時間間隔後,每當需要觸發Checkpoint時,會向Flink程式運作時的多個分布式的Stream Source中插入一個Barrier标記,這些Barrier會根據Stream中的資料記錄一起流向下遊的各個Operator。當一個Operator接收到一個Barrier時,它會暫停處理Steam中新接收到的資料記錄。因為一個Operator可能存在多個輸入的Stream,而每個Stream中都會存在對應的Barrier,該Operator要等到所有的輸入Stream中的Barrier都到達。當所有Stream中的Barrier都已經到達該Operator,這時所有的Barrier在時間上看來是同一個時刻點(表示已經對齊),在等待所有Barrier到達的過程中,Operator的Buffer中可能已經緩存了一些比Barrier早到達Operator的資料記錄(Outgoing Records),這時該Operator會将資料記錄(Outgoing Records)發射(Emit)出去,作為下遊Operator的輸入,最後将Barrier對應Snapshot發射(Emit)出去作為此次Checkpoint的結果資料。
Checkpoint 其他的屬性包括:
精确一次(exactly-once)對比至少一次(at-least-once):你可以選擇向 enableCheckpointing(long interval, CheckpointingMode mode) 方法中傳入一個模式來選擇使用兩種保證等級中的哪一種。對于大多數應用來說,精确一次是較好的選擇。至少一次可能與某些延遲超低(始終隻有幾毫秒)的應用的關聯較大。
checkpoint 逾時:如果 checkpoint 執行的時間超過了該配置的門檻值,還在進行中的 checkpoint 操作就會被抛棄。
checkpoints 之間的最小時間:該屬性定義在 checkpoint 之間需要多久的時間,以確定流應用在 checkpoint 之間有足夠的進展。如果值設定為了 5000,無論 checkpoint 持續時間與間隔是多久,在前一個 checkpoint 完成時的至少五秒後會才開始下一個 checkpoint。
并發 checkpoint 的數目: 預設情況下,在上一個 checkpoint 未完成(失敗或者成功)的情況下,系統不會觸發另一個 checkpoint。這確定了拓撲不會在 checkpoint 上花費太多時間,進而影響正常的處理流程。不過允許多個 checkpoint 并行進行是可行的,對于有确定的處理延遲(例如某方法所調用比較耗時的外部服務),但是仍然想進行頻繁的 checkpoint 去最小化故障後重跑的 pipelines 來說,是有意義的。
externalized checkpoints: 你可以配置周期存儲 checkpoint 到外部系統中。Externalized checkpoints 将他們的中繼資料寫到持久化存儲上并且在 job 失敗的時候不會被自動删除。這種方式下,如果你的 job 失敗,你将會有一個現有的 checkpoint 去恢複。更多的細節請看 Externalized checkpoints 的部署文檔。
在 checkpoint 出錯時使 task 失敗或者繼續進行 task:他決定了在 task checkpoint 的過程中發生錯誤時,是否使 task 也失敗,使失敗是預設的行為。 或者禁用它時,這個任務将會簡單的把 checkpoint 錯誤資訊報告給 checkpoint coordinator 并繼續運作。
優先從 checkpoint 恢複(prefer checkpoint for recovery):該屬性确定 job 是否在最新的 checkpoint 回退,即使有更近的 savepoint 可用,這可以潛在地減少恢複時間(checkpoint 恢複比 savepoint 恢複更快)。
儲存多個Checkpoint
預設情況下,如果設定了Checkpoint選項,則Flink隻保留最近成功生成的1個Checkpoint,而當Flink程式失敗時,可以從最近的這個Checkpoint來進行恢複。但是,如果我們希望保留多個Checkpoint,并能夠根據實際需要選擇其中一個進行恢複,這樣會更加靈活,比如,我們發現最近4個小時資料記錄處理有問題,希望将整個狀态還原到4小時之前。
Flink可以支援保留多個Checkpoint,需要在Flink的配置檔案conf/flink-conf.yaml中,添加如下配置,指定最多需要儲存Checkpoint的個數:
保留了最近的20個Checkpoint。如果希望會退到某個Checkpoint點,隻需要指定對應的某個Checkpoint路徑即可實作。
從Checkpoint進行恢複
從指定的checkpoint處啟動,最近的一個/flink/checkpoints/workFlowCheckpoint/339439e2a3d89ead4d71ae3816615281/chk-1740584啟動,通常需要先停掉目前運作的flink-session,然後通過指令啟動:
可以把指令放到腳本裡面,每次直接執行<code>checkpoint</code>恢複腳本即可:
儲存點機制 (Savepoints)是檢查點機制的一種特殊的實作,它允許通過手工的方式來觸發 Checkpoint,并将結果持久化存儲到指定路徑中,主要用于避免 Flink 叢集在重新開機或更新時導緻狀态丢失。示例如下:
手動savepoint
成功觸發savepoint通常會提示:<code>Savepoint completed. Path: hdfs://path...</code>:
手動取消任務
與<code>checkpoint</code>異常停止或者手動<code>Kill</code>掉不一樣,對于<code>savepoint</code>通常是我們想要手動停止任務,然後更新代碼,可以使用<code>flink cancel ...</code>指令:
從指定savepoint啟動job
Flink 提供了多種 state backends,它用于指定狀态的存儲方式和位置。
狀态可以位于 Java 的堆或堆外記憶體。取決于 state backend,Flink 也可以自己管理應用程式的狀态。為了讓應用程式可以維護非常大的狀态,Flink 可以自己管理記憶體(如果有必要可以溢寫到磁盤)。預設情況下,所有 Flink Job 會使用配置檔案 flink-conf.yaml 中指定的 state backend。
但是,配置檔案中指定的預設 state backend 會被 Job 中指定的 state backend 覆寫。
MemoryStateBackend
預設的方式,即基于 JVM 的堆記憶體進行存儲,主要适用于本地開發和調試。
FsStateBackend
基于檔案系統進行存儲,可以是本地檔案系統,也可以是 HDFS 等分布式檔案系統。 需要注意而是雖然選擇使用了 FsStateBackend ,但正在進行的資料仍然是存儲在 TaskManager 的記憶體中的,隻有在 checkpoint 時,才會将狀态快照寫入到指定檔案系統上。
RocksDBStateBackend
RocksDBStateBackend 是 Flink 内置的第三方狀态管理器,采用嵌入式的 key-value 型資料庫 RocksDB 來存儲正在進行的資料。等到 checkpoint 時,再将其中的資料持久化到指定的檔案系統中,是以采用 RocksDBStateBackend 時也需要配置持久化存儲的檔案系統。之是以這樣做是因為 RocksDB 作為嵌入式資料庫安全性比較低,但比起全檔案系統的方式,其讀取速率更快;比起全記憶體的方式,其存儲空間更大,是以它是一種比較均衡的方案。
Flink 支援使用兩種方式來配置後端管理器:
第一種方式:基于代碼方式進行配置,隻對目前作業生效:
配置 RocksDBStateBackend 時,需要額外導入下面的依賴:
第二種方式:基于 flink-conf.yaml 配置檔案的方式進行配置,對所有部署在該叢集上的作業都生效:
在真實應用中,流處理應用除了流處理器以外還包含了資料源(例如 Kafka)和輸出到持久化系統。
端到端的一緻性保證,意味着結果的正确性貫穿了整個流處理應用的始終;每一個元件都保證了它自己的一緻性,整個端到端的一緻性級别取決于所有元件中一緻性最弱的元件。具體可以劃分如下:
内部保證:依賴checkpoint
source 端:需要外部源可重設資料的讀取位置
sink 端:需要保證從故障恢複時,資料不會重複寫入外部系統。
而對于sink端,又有兩種具體的實作方式:
幂等(Idempotent)寫入:所謂幂等操作,是說一個操作,可以重複執行很多次,但隻導緻一次結果更改,也就是說,後面再重複執行就不起作用了。
事務性(Transactional)寫入:需要建構事務來寫入外部系統,建構的事務對應着 checkpoint,等到 checkpoint 真正完成的時候,才把所有對應的結果寫入 sink 系統中。
對于事務性寫入,具體又有兩種實作方式:預寫日志(WAL)和兩階段送出(2PC)。Flink DataStream API 提供了GenericWriteAheadSink 模闆類和 TwoPhaseCommitSinkFunction 接口,可以友善地實作這兩種方式的事務性寫入。
端到端的狀态一緻性的實作,需要每一個元件都實作,對于Flink + Kafka的資料管道系統(Kafka進、Kafka出)而言,各元件怎樣保證exactly-once語義呢?
内部:利用checkpoint機制,把狀态存盤,發生故障的時候可以恢複,保證内部的狀态一緻性
source:kafka consumer作為source,可以将偏移量儲存下來,如果後續任務出現了故障,恢複的時候可以由連接配接器重置偏移量,重新消費資料,保證一緻性
sink:kafka producer作為sink,采用兩階段送出 sink,需要實作一個TwoPhaseCommitSinkFunction内部的checkpoint機制。
<code>EXACTLY_ONCE</code>語義簡稱EOS,指的是每條輸入消息隻會影響最終結果一次,注意這裡是影響一次,而非處理一次,Flink一直宣稱自己支援EOS,實際上主要是對于Flink應用内部來說的,對于外部系統(端到端)則有比較強的限制
外部系統寫入支援幂等性
外部系統支援以事務的方式寫入
Kafka在0.11版本之前隻能保證<code>At-Least-Once</code>或<code>At-Most-Once</code>語義,從0.11版本開始,引入了幂等發送和事務,進而開始保證<code>EXACTLY_ONCE</code>語義。
Maven依賴
開始支援的版本
生産/消費 類名
kafka版本
注意
flink-connector-kafka-0.8_2.11
1.0.0
FlinkKafkaConsumer08<br>FlinkKafkaProducer08
0.8.x
使用Kafka内部SimpleConsumer API. Flink把Offsets送出到ZK
flink-connector-kafka-0.9_2.11
FlinkKafkaConsumer09<br>FlinkKafkaProducer09
0.9.x
使用新版Kafka Consumer API.
flink-connector-kafka-0.10_2.11
1.2.0
FlinkKafkaConsumer010<br>FlinkKafkaProducer010
0.10.x
支援Kafka生産/消費消息帶時間戳
flink-connector-kafka-0.11_2.11
1.4.0
FlinkKafkaConsumer011<br>FlinkKafkaProducer011
0.11.x
由于0.11.x Kafka不支援scala 2.10。此連接配接器支援Kafka事務消息傳遞,以便為生産者提供exactly once語義。
<code>flink-connector-kafka_2.11</code>
1.7.0
FlinkKafkaConsumer<br>FlinkKafkaProducer
>=1.0.0
高版本向後相容。但是,對于Kafka 0.11.x和0.10.x版本,我們建議分别使用專用的<code>flink-connector-Kafka-0.11_2.11</code>和<code>link-connector-Kafka-0.10_2.11</code>
Flink在1.4.0版本引入了TwoPhaseCommitSinkFunction接口,封裝了兩階段送出邏輯,并在Kafka Sink connector中實作了TwoPhaseCommitSinkFunction,依賴Kafka版本為0.11+
Flink由JobManager協調各個TaskManager進行checkpoint存儲,checkpoint儲存在 StateBackend中,預設StateBackend是記憶體級的,也可以改為檔案級的進行持久化儲存。
當 checkpoint 啟動時,JobManager 會将檢查點分界線(barrier)注入資料流;barrier會在算子間傳遞下去。
每個算子會對目前的狀态做個快照,儲存到狀态後端。對于source任務而言,就會把目前的offset作為狀态儲存起來。下次從checkpoint恢複時,source任務可以重新送出偏移量,從上次儲存的位置開始重新消費資料。
每個内部的 transform 任務遇到 barrier 時,都會把狀态存到 checkpoint 裡。
sink 任務首先把資料寫入外部 kafka,這些資料都屬于預送出的事務(還不能被消費);當遇到 barrier時,把狀态儲存到狀态後端,并開啟新的預送出事務。
當所有算子任務的快照完成,也就是這次的 checkpoint 完成時,JobManager 會向所有任務發通知,确認這次 checkpoint 完成。當sink 任務收到确認通知,就會正式送出之前的事務,kafka 中未确認的資料就改為“已确認”,資料就真正可以被消費了。
是以看到,執行過程實際上是一個兩段式送出,每個算子執行完成,會進行“預送出”,直到執行完sink操作,會發起“确認送出”,如果執行失敗,預送出會放棄掉。
具體的兩階段送出步驟總結如下:
第一條資料來了之後,開啟一個 kafka 的事務(transaction),正常寫入 kafka 分區日志但标記為未送出,這就是“預送出”, jobmanager 觸發 checkpoint 操作,barrier 從 source 開始向下傳遞,遇到 barrier 的算子将狀态存入狀态後端,并通知 jobmanager
sink 連接配接器收到 barrier,儲存目前狀态,存入 checkpoint,通知 jobmanager,并開啟下一階段的事務,用于送出下個檢查點的資料
jobmanager 收到所有任務的通知,發出确認資訊,表示 checkpoint 完成
sink 任務收到 jobmanager 的确認資訊,正式送出這段時間的資料
外部kafka關閉事務,送出的資料可以正常消費了。
是以也可以看到,如果當機需要通過StateBackend進行恢複,隻能恢複所有确認送出的操作。
前面表格總結的可以看出,Kafka在0.11版本之前隻能保證<code>At-Least-Once</code>或<code>At-Most-Once</code>語義,從0.11版本開始,引入了幂等發送和事務,進而開始保證<code>EXACTLY_ONCE</code>語義。
在未引入幂等性時,Kafka正常發送和重試發送消息流程圖如下:
為了實作Producer的幂等語義,Kafka引入了Producer ID(即PID)和Sequence Number。每個新的Producer在初始化的時候會被配置設定一個唯一的PID,該PID對使用者完全透明而不會暴露給使用者。
Producer發送每條消息<Topic, Partition>對于Sequence Number會從0開始單調遞增,broker端會為每個<PID, Topic, Partition>維護一個序号,每次commit一條消息此序号加一,對于接收的每條消息,如果其序号比Broker維護的序号(即最後一次Commit的消息的序号)大1以上,則Broker會接受它,否則将其丢棄:
序号比Broker維護的序号大1以上,說明存在亂序。
序号比Broker維護的序号小,說明此消息以及被儲存,為重複資料。
有了幂等性,Kafka正常發送和重試發送消息流程圖如下:
事務是指所有的操作作為一個原子,要麼都成功,要麼都失敗,而不會出現部分成功或部分失敗的可能。舉個例子,比如小明給小王轉賬1000元,那首先小明的賬戶會減去1000,然後小王的賬戶會增加1000,這兩個操作就必須作為一個事務,否則就會出現隻減不增或隻增不減的問題,是以要麼都失敗,表示此次轉賬失敗。要麼都成功,表示此次轉賬成功。分布式下為了保證事務,一般采用兩階段送出協定。
為了解決跨session和所有分區不能EXACTLY-ONCE問題,Kafka從0.11開始引入了事務。
為了支援事務,Kafka引入了Transacation Coordinator來協調整個事務的進行,并可将事務持久化到内部topic裡,類似于offset和group的儲存。
使用者為應用提供一個全局的Transacation ID,應用重新開機後Transacation ID不會改變。為了保證新的Producer啟動後,舊的具有相同Transaction ID的Producer即失效,每次Producer通過Transaction ID拿到PID的同時,還會擷取一個單調遞增的epoch。由于舊的Producer的epoch比新Producer的epoch小,Kafka可以很容易識别出該Producer是老的Producer并拒絕其請求。有了Transaction ID後,Kafka可保證:
跨Session的資料幂等發送。當具有相同Transaction ID的新的Producer執行個體被建立且工作時,舊的Producer停止工作。
跨Session的事務恢複。如果某個應用執行個體當機,新的執行個體可以保證任何未完成的舊的事務要麼Commit要麼Abort,使得新執行個體從一個正常狀态開始工作。
KIP-98 對<code>Kafka</code>事務原理進行了詳細介紹,完整的流程圖如下:
Producer向任意一個brokers發送 FindCoordinatorRequest請求來擷取Transaction Coordinator的位址;
找到Transaction Coordinator後,具有幂等特性的Producer必須發起InitPidRequest請求以擷取PID。
調用beginTransaction()方法開啟一個事務,Producer本地會記錄已經開啟了事務,但Transaction Coordinator隻有在Producer發送第一條消息後才認為事務已經開啟。
Consume-Transform-Produce這一階段,包含了整個事務的資料處理過程,并且包含了多種請求。
送出或復原事務 一旦上述資料寫入操作完成,應用程式必須調用KafkaProducer的commitTransaction方法或者abortTransaction方法以結束目前事務。
兩階段送出指的是一種協定,經常用來實作分布式事務,可以簡單了解為預送出+實際送出,一般分為協調器Coordinator(以下簡稱C)和若幹事務參與者Participant(以下簡稱P)兩種角色。
C先将prepare請求寫入本地日志,然後發送一個prepare的請求給P
P收到prepare請求後,開始執行事務,如果執行成功傳回一個Yes或OK狀态給C,否則傳回No,并将狀态存到本地日志。
C收到P傳回的狀态,如果每個P的狀态都是Yes,則開始執行事務Commit操作,發Commit請求給每個P,P收到Commit請求後各自執行Commit事務操作。如果至少一個P的狀态為No,則會執行Abort操作,發Abort請求給每個P,P收到Abort請求後各自執行Abort事務操作。
注:C或P把發送或接收到的消息先寫到日志裡,主要是為了故障後恢複用,類似WAL
橫向擴充相關來于:Flink狀态管理詳解:Keyed State和Operator List State深度解析
checkpoint 相關來于:Apache Flink v1.10 官方中文文檔
狀态一緻性相關來于:再忙也需要看的Flink狀态管理