原文:https://zybuluo.com/hanbingtao/note/541458
循環神經網絡也可以畫成下面這個樣子:
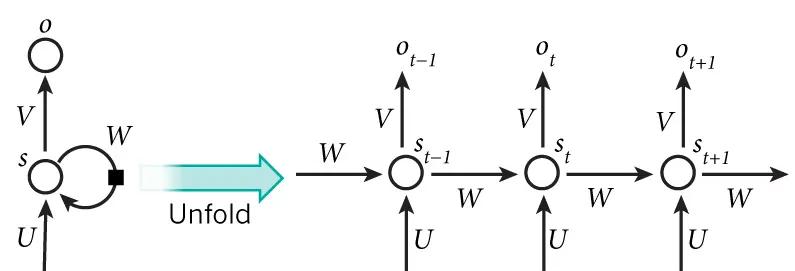
對于語言模型來說,很多時候光看前面的詞是不夠的,比如下面這句話:
我的手機壞了,我打算____一部新手機。
可以想象,如果我們隻看橫線前面的詞,手機壞了,那麼我是打算修一修?換一部新的?還是大哭一場?這些都是無法确定的。但如果我們也看到了橫線後面的詞是『一部新手機』,那麼,橫線上的詞填『買』的機率就大得多了。
在上一小節中的基本循環神經網絡是無法對此進行模組化的,是以,我們需要雙向循環神經網絡,如下圖所示:

前面我們介紹的循環神經網絡隻有一個隐藏層,我們當然也可以堆疊兩個以上的隐藏層,這樣就得到了深度循環神經網絡。如下圖所示:
BPTT算法是針對循環層的訓練算法,它的基本原理和BP算法是一樣的,也包含同樣的三個步驟:
前向計算每個神經元的輸出值;
反向計算每個神經元的誤差項值,它是誤差函數E對神經元j的權重輸入的偏導數;
計算每個權重的梯度。
最後再用随機梯度下降算法更新權重。
現在,我們介紹一下基于RNN語言模型。我們首先把詞依次輸入到循環神經網絡中,每輸入一個詞,循環神經網絡就輸出截止到目前為止,下一個最可能的詞。例如,當我們依次輸入:
我 昨天 上學 遲到 了
神經網絡的輸出如下圖所示:
可以用下面的圖來直覺的表示:
使用這種向量化方法,我們就得到了一個高維、稀疏的向量(稀疏是指絕大部分元素的值都是0)。
其中,s和e是兩個特殊的詞,分别表示一個序列的開始和結束。
我們知道,神經網絡的輸入和輸出都是向量,為了讓語言模型能夠被神經網絡處理,我們必須把詞表達為向量的形式,這樣神經網絡才能處理它。
神經網絡的輸入是詞,我們可以用下面的步驟對輸入進行向量化:
建立一個包含所有詞的詞典,每個詞在詞典裡面有一個唯一的編号。
任意一個詞都可以用一個N維的one-hot向量來表示。
語言模型要求的輸出是下一個最可能的詞,我們可以讓循環神經網絡計算計算詞典中每個詞是下一個詞的機率,這樣,機率最大的詞就是下一個最可能的詞。是以,神經網絡的輸出向量也是一個N維向量,向量中的每個元素對應着詞典中相應的詞是下一個詞的機率。如下圖所示:
最後,我們使用交叉熵誤差函數作為優化目标,對模型進行優化。
在實際工程中,我們可以使用大量的語料來對模型進行訓練,擷取訓練資料和訓練的方法都是相同的。
本文轉自張昺華-sky部落格園部落格,原文連結:http://www.cnblogs.com/bonelee/p/7717569.html,如需轉載請自行聯系原作者