導語
在騰訊雲MongoDB的營運過程中,發現較多使用者對副本集主從複制流程的了解還有些偏差。這些偏差在一定程度上影響了應用程式設計和平時的營運。
本文會聚焦下面幾個問題:
- 寫大多數節點是如何完成的?
- 從節點拉取oplog和回放oplog是否會有阻塞,如何調優?
- Mongo Shell 上執行 printSlaveReplicationInfo 指令看主從延遲,系統壓力不大時也在秒級,是否正常?
- printSlaveReplicationInfo 為什麼不能優化到毫秒級别?
- 在從節點上執行 printSlaveReplicationInfo 指令,發現從節點的資料領先主節點,是否正常?
- 什麼是鍊式複制?哪些場景适合開啟,哪些不适合?
主從複制架構分析
主從複制大緻流程
MongoDB副本集模式下,使用者向主節點寫入資料,并記錄oplog. 從節點通過oplog進行資料同步,最終保證副本集中的各個節點的資料一緻性。
用戶端可以指定寫入請求的一緻性級别(WriteConcern),比如對于資料一緻性較高的場景,可以設定資料複制到“大多數”節點才傳回成功。這樣能夠保證即使主節點重新開機後不會復原掉之前寫入的資料。
一個常見的誤解:寫大多數節點模型下,用戶端需要将資料發到多個節點,是否會增加用戶端的負擔?
“寫大多數”請求的流程如下,用戶端隻需要向主節點寫入資料即可(不需也不能向從節點直接寫資料);從節點進行oplog同步之後,會将自身已經同步的oplog時間點通知給主節點;主節點維護了副本集中各個從節點的oplog同步情況,如果确定資料已經到了大多數節點上(包括自己),則給用戶端傳回成功。如果資料同步發生了異常,或者同步太慢,則可能觸發逾時。
同理,ReadConcern Majority也不是用戶端去讀多個節點,這裡不詳細讨論
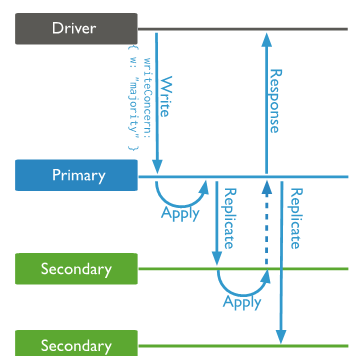
副本集資料同步示意圖
詳細的主從同步流程如下圖所示(以 1 Primary 1 Secondary 為例):

主從複制細節
主要步驟如下:
- 主節點接受使用者的寫請求,更新使用者表和oplog表。如果使用者設定了 writeConcern:majority,此時由于不符合寫入成功的傳回條件,處理線程會阻塞
- 從節點上的 "rsBackgroundSync" 背景線程通過 find/getmore 指令到主節點上擷取oplog,并放入到 OplogBuffer中;"replBatcher" 線程感覺到OplogBuffer中的資料并消費,儲存到OpQueue中;"OplogApplier" 線程感覺OpQueue中的新資料,通過多個(預設16個)worker線程回放Oplog,并更新lastAppliedOpTime 和 lastDurableOpTime
- 從節點上的 "SyncSourceFeedback" 背景線程感覺到有新資料寫入成功,将自身最新的 lastAppliedOpTime和lastDurableOpTime 等資訊通過 "replSetUpdatePosition" 内部指令傳回給主節點
- 主節點接受到各個從節點 最新的 lastAppliedOpTime 和 lastDurableOpTime(writeConcernMajorityJournalDefault 配置項決定了具體以哪個時間為準),計算大多數節點(包括自己)目前的資料同步進展,并更新 lastCommittedOpTime, 然後喚醒正在等待的請求處理線程
- 主節點上的使用者處理線程給使用者傳回處理結果
常見誤解說明:
誤解1:從節點拉取 oplog 回放完之後,才會拉取下一批 oplog
真實情況:拉取和回放屬于不同的線程,互相不會阻塞
誤解2:對參數 replBatchLimitBytes(預設100MB) 和 replBatchLimitOperations(預設5000) 存在誤解,認為回放線程必須累積到這麼多oplog後才會批量回放
真實情況:回放線程盡量累積大量資料才回放(批量并發執行效率高)。但是如果oplog比較少,會提前傳回。但是極端情況下,可能會有最多阻塞1秒的情況(具體參考 sync_tail.cpp 中的 SyncTail::tryPopAndWaitForMore實作)。關于這一點,下一篇文章會結合代碼和例子進行詳細分析
誤解3:從節點通過心跳傳回同步進度,主節點根據心跳資訊決定 writeConcern:majority 是否傳回
真實情況:從節點通過 replSetUpdatePosition 及時上報同步情況。心跳周期太長,預設 2 秒一次,是以根據心跳資訊顯然是不合适的
性能調優建議
- 根據實際情況,調整回放線程的個數,預設 16 個。對應 replWriterThreadCount 參數,可在程式啟動時指定。
- 根據實際情況,調整批量回放的最大 oplog 條數(預設 5000)和最大 oplog 大小(預設 100MB)。前者對應 replBatchLimitOperations 參數,可在程式啟動時或者運作過程中指定;後者對應 replBatchLimitBytes 參數,在 官方文檔中說明可以動态修改,但是實測發現并不成功,代碼中也沒有找到修改的接口。如果有變更需求,可以直接修改 sync_tail.h 中 replBatchLimitBytes 的初始化代碼
主從延遲指令解析
MongoDB 管理者使用 printSlaveReplicationInfo 指令來觀察主從延遲情況
printSlaveReplicationInfo 是 MongoShell 封裝的 js 指令,可以在任意一個MongoShell用戶端上直接執行db.printSlaveReplicationInfo 檢視 js 源代碼。如下所示:
function () {
var startOptimeDate = null; // 基準optime
var primary = null;
// 根據基準optime,列印節點的延遲情況,精确到秒
function getReplLag(st) {
assert(startOptimeDate, "how could this be null (getReplLag startOptimeDate)");
print("\tsyncedTo: " + st.toString());
var ago = (startOptimeDate - st) / 1000;
var hrs = Math.round(ago / 36) / 100;
var suffix = "";
if (primary) {
suffix = "primary ";
} else {
suffix = "freshest member (no primary available at the moment)";
}
print("\t" + Math.round(ago) + " secs (" + hrs + " hrs) behind the " + suffix);
}
function getMaster(members) {
for (i in members) {
var row = members[i];
if (row.state === 1) {
return row;
}
}
return null;
}
function g(x) {
assert(x, "how could this be null (printSlaveReplicationInfo gx)");
print("source: " + x.host);
if (x.syncedTo) {
var st = new Date(DB.tsToSeconds(x.syncedTo) * 1000);
getReplLag(st);
} else {
print("\tdoing initial sync");
}
}
function r(x) {
assert(x, "how could this be null (printSlaveReplicationInfo rx)");
if (x.state == 1 || x.state == 7) { // ignore primaries (1) and arbiters (7)
return;
}
print("source: " + x.name);
if (x.optime) {
getReplLag(x.optimeDate);
} else {
print("\tno replication info, yet. State: " + x.stateStr);
}
}
var L = this.getSiblingDB("local");
if (L.system.replset.count() != 0) {
var status = this.adminCommand({'replSetGetStatus': 1}); // replSetGetStatus指令的結果,作為本次計算的資料源
primary = getMaster(status.members);
if (primary) {
startOptimeDate = primary.optimeDate; //如果主節點存在,則選擇主節點的 optime 為基準 optime
}
// no primary, find the most recent op among all members
else {
startOptimeDate = new Date(0, 0);
for (i in status.members) { // 如果主節點不存在,則選擇最新的 optime 為基準 optime
if (status.members[i].optimeDate > startOptimeDate) {
startOptimeDate = status.members[i].optimeDate;
}
}
}
for (i in status.members) { //對除 primary 和 arbiter 的節點,列印延遲情況
r(status.members[i]);
}
}
} 複制
總體來說,根據
replSetGetStatus
指令中每個 member 的 optimeDate 來計算延遲。分析核心代碼發現,
replSetGetStatus
指令通過心跳資訊來擷取其他節點的 optimeDate。
可以得出,
printSlaveReplicationInfo
指令的結果依賴于心跳資訊。
MongoDB副本集心跳示意圖
預設配置下,節點之間的心跳間隔是 2 秒,也就是說
printSlaveReplicationInfo
展示的可能是“過期”資訊,存在一定的誤差。
比如有一個持續被寫入的副本集,主節點在 t1 時刻維護的還是 t0 時刻的心跳資訊,則
printSlaveReplicationInfo
指令會顯示從節點比主節點落後 1 秒,在主節點很快接受到從節點更新的資訊之後,主從延遲又會馬上變為 0 秒。出現主從延遲“抖動”的情況。
同理,按照從節點的視角來看,在 t1 時刻已經從主節點同步到了最新的資料,但是維護的主節點心跳還是 t0 時刻的“過期”資料。此時會認為主節點的 optimeDate 還是 t0,是以在從節點上執行
printSlaveReplicationInfo
指令,會看到從節點“領先”主節點 1 秒的奇怪現象。
特殊說明
心跳資訊維護在 TopologyCoordinator::memberData 中
核心對主節點維護的 memberData 進行了優化:除了正常的心跳請求會更新之外,從節點發送過來的 replSetUpdatePosition 也會更新 memberData 中的資料。是以在主節點上執行 printSlaveReplicationInfo 指令 相對來說 已經盡量做到準确了。
總結:心跳資訊帶來的不确定性,會導緻 printSlaveReplicationInfo 的結果存在誤差
延遲指令的精度問題
MongoDB 使用了 BSON 格式的 TimeStamp,是一個 64 bit 的值:
- 高 32 bit 存放 UNIX 秒級時間
- 低 32 bit 存放 一個遞增的計數器,來區分這一秒内的多條oplog
是以,TimeStamp 能夠表示的精度隻有秒級。
是以,printSlaveReplicationInfo 指令看到的秒級延遲不能說明主從延遲真的是秒級。除了前文說到的心跳原因,TimeStamp 的精度問題也會給觀測帶來誤差。
鍊式複制
什麼是鍊式複制
在MongoDB副本集模式中,從節點除了可以到主節點同步資料外,還可以到資料較新的另外一個從節點同步資料。
如下圖所示,第2個從節點可以切換同步源到第1個從節點,這樣副本集的同步關系變成了Primary1-->Secondary1-->Secondary2 鍊式結構
image.png
如何開啟
- 通過 rs.reconfig() 指令将
settings.chainingAllowed
- 根據具體的使用場景,可以在從節點上執行 rs.syncFrom 指令指定同步源。如果不手動指定,則MongoDB背景線程會根據各個節點的 oplog 時間進行選擇和切換。
适合開啟鍊式複制的場景
鍊式複制帶來的好處是:不用所有從節點都到主節點同步資料,可以有效減少主節點的壓力。
對于寫完主節點即傳回,并讀主節點的業務來說,開啟鍊式複制能在一定程度上提升性能。
适合關閉鍊式複制的場景
鍊式複制帶來的缺陷是:
- 資料複制的鍊路變長。對于 WriteConcern 設定比較大的請求,處理時長會變長。
-
讀oplog的壓力從主節點轉移到了部分從節點上,會一定程度上影響從節點的性能。
是以,對于 {WriteConcern:majority} 的業務場景,建議關閉鍊式複制;對于寫主讀從的業務場景,可以根據實際的請求量,考慮是否關閉鍊式複制。
參考文檔
GitHub: replication-internals