作者:閑魚技術——景松
1. 背景
在2020年年初的時候接手了閑魚的消息,當時的消息存在各種問題,網上的輿情也是接連不斷:“閑魚消息經常丢失”、“消息使用者頭像亂了”、“訂單狀态不對”(相信現在看文章的你還在吐槽閑魚的消息)。是以閑魚的穩定性是一個亟待解決的問題,我們調研了集團的一些解決方案,例如釘釘的IMPass。直接遷移的成本和風險都是比較大,包括服務端資料需要雙寫、新老版本相容等。
那基于閑魚現有的消息架構和體系,如何來保證它的穩定性?治理應該從哪裡開始?現在閑魚的穩定性是什麼樣的?如何衡量穩定性?希望這篇文章,能讓大家看到一個不一樣的閑魚消息。
2. 行業方案
消息的投遞鍊路大緻分為三步:發送者發送,服務端接收然後落庫,服務端通知接收端。特别是移動端的網絡環境比較複雜,可能你發着消息,網絡突然斷掉了;可能消息正在發送中,網絡突然好了,需要重發。
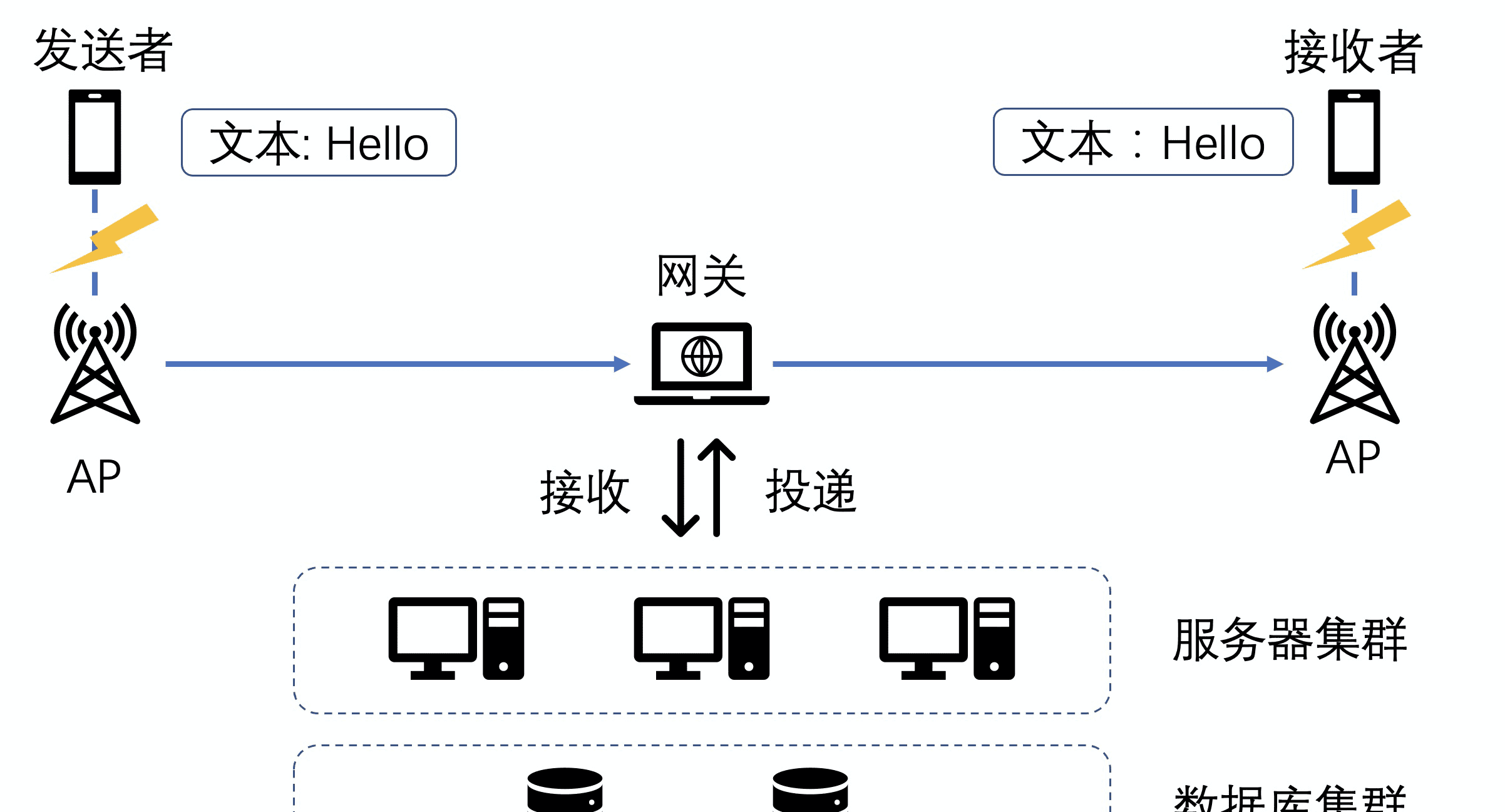
在如此複雜的網絡環境下,是如何穩定可靠的進行消息投遞的?對發送者來說,它不知道消息是否有送達,要想做到确定送達,就需要加一個響應機制,類似下面的響應邏輯:
- 發送者發送了一條消息“Hello”,進入等待狀态。
- 接收者收到這條消息“Hello”,然後告訴發送者說我已經收到這條消息了的确認資訊。
- 發送者接收到确認資訊後,這個流程就算完成了,否則會重試。
上面流程看似簡單,關鍵是中間有個服務端轉發過程,問題就在于誰來回這個确認資訊,什麼時候回這個确認資訊。網上查到比較多的是如下一個必達模型,如下圖所示:

[發送流程]
-
A
IM-server
msg:R1
-
IM-server
A
msg:A1
- 如果此時
B
IM-server
B
msg:N1
B
[接收流程]
-
B
IM-server
ack:R2
-
IM-server
B
ack:A2
- 則
IM-server
A
ack:N2
一個可信的消息送達系統就是靠的6條封包來保證的,有這個投遞模型來決定消息的必達,中間任何一個環節出錯,都可以基于這個request-ack機制來判定是否出錯并重試。看下在第4.2章中,也是參考了上面這個模型,用戶端發送的邏輯是直接基于http的是以暫時不用做重試,主要是在服務端往用戶端推送的時候,會加上重試的邏輯。
3. 閑魚消息的問題
剛接手閑魚消息,沒有穩定相關的資料,是以第一步還是要對閑魚消息做一個系統的排查,首先對消息做了全鍊路埋點。
基于消息的整個鍊路,我們梳理出來了幾個關鍵的名額:發送成功率、消息到達率、用戶端落庫率。整個資料的統計都是基于埋點來做的。在埋點的過程總,發現了一個很大的問題:閑魚的消息沒有一個全局唯一的ID,導緻在全鍊路埋點的過程中,無法唯一确定這條消息的生命周期。
3.1 消息唯一性問題
之前閑魚的消息是通過3個變量來唯一确定一個消息
- SessionID: 目前會話的ID
- SeqID:使用者目前本地發送的消息序号,服務端是不關心此資料,完全是透傳
- Version:這個比較重要,是消息在目前會話中的序号,已服務端為準,但是用戶端也會生成一個假的version
以上圖為例,當A和B同時發送消息的時候,都會在本地生成如上幾個關鍵資訊,當A發送的消息(黃色)首先到達服務端,因為前面沒有其他version的消息,是以會将原資料傳回給A,用戶端A接收到消息的時候,再跟本地的消息做合并,隻會保留一條消息。同時服務端也會将此消息發送給B,因為B本地也有一個version=1的消息,是以服務端過來的消息就會被過濾掉,這就出現消息丢失的問題。
當B發送消息到達服務端後,因為已經有version=1的消息,是以服務端會将B的消息version遞增,此時消息的version=2。這條消息發送給A,和本地消息可以正常合并。但是當此消息傳回給B的時候,和本地的消息合并,會出現2條一樣的消息,出現消息重複,這也是為什麼閑魚之前總是出現消息丢失和消息重複最主要的原因。
3.2 消息推送邏輯問題
之前閑魚的消息的推送邏輯也存在很大的問題,發送端使用http請求,發送消息内容,基本不會出問題,問題是出現在服務端給另外一端推送的時候。如下圖所示,
服務端在給用戶端推送的時候,會先判斷此時用戶端是否線上,如果線上才會推送,如果不線上就會推離線消息。這個做法就非常的簡單粗暴。長連接配接的狀态如果不穩定,導緻用戶端真實狀态和服務端的存儲狀态不一緻,就導緻消息不會推送到端上。
3.3 用戶端邏輯問題
除了以上跟服務端有關系外,還有一類問題是用戶端本身設計的問題,可以歸結為以下幾種情況:
- 多線程問題
回報消息清單頁面會出現布局錯亂,本地資料還沒有完全初始化好,就開始渲染界面
- 未讀數和小紅點的計數不準确
本地的顯示資料和資料庫存儲的不一緻。
- 消息合并問題
本地在合并消息的時候,是分段合并的,不能保證消息的連續性和唯一性。
諸如以上的幾種情況,我們首先是對用戶端的代碼做了梳理與重構,架構如下圖所示:
4. 我們的解法 - 引擎更新
進行治理的第一步就是,解決閑魚消息的唯一性的問題。我們也調研了釘釘的方案,釘釘是服務端全局維護消息的唯一ID,考慮到閑魚消息的曆史包袱,我們這邊采用UUID作為消息的唯一ID,這樣就可以在消息鍊路埋點以及去重上得到很大的改善。
4.1 消息唯一性
在新版本的APP上面,用戶端會生成一個uuid,對于老版本無法生成的情況,服務端也會補充上相關資訊。
消息的ID類似
a1a3ffa118834033ac7a8b8353b7c6d9
,用戶端在接收到消息後,會先根據MessageID來去重,然後基于Timestamp排序就可以了,雖然用戶端的時間可能不一樣,但是重複的機率還是比較小。
- (void)combileMessages:(NSArray<PMessage*>*)messages {
...
// 1. 根據消息MessageId進行去重
NSMutableDictionary *messageMaps = [self containerMessageMap];
for (PMessage *message in msgs) {
[messageMaps setObject:message forKey:message.messageId];
}
// 2. 消息合并後排序
NSMutableArray *tempMsgs = [NSMutableArray array];
[tempMsgs addObjectsFromArray:messageMaps.allValues];
[tempMsgs sortUsingComparator:^NSComparisonResult(PMessage * _Nonnull obj1, PMessage * _Nonnull obj2) {
// 根據消息的timestamp進行排序
return obj1.timestamp > obj2.timestamp;
}];
...
} 4.2 重發重連
基于#2中的重發重連模型,閑魚完善了服務端的重發的邏輯,用戶端完善了重連的邏輯。
- 用戶端會定時檢測ACCS長連接配接是否聯通
- 服務端會檢測裝置是否線上,如果線上會推送消息,并會有逾時等待
- 用戶端接收到消息之後,會傳回一個Ack
已經有小夥伴發表了一篇文章:
《向消息延遲說bybye:閑魚消息及時到達方案(詳細)》,講解了下關于網絡不穩定給閑魚消息帶來的問題,在這裡就不多贅述了。
4.3 資料同步
重發重連是解決的基礎網絡層的問題,接下來就要看下業務層的問題,很多複雜情況是通過在業務層增加相容代碼來解決的,閑魚消息的資料同步就是一個很典型的場景。在完善資料同步的邏輯之前,我們也調研過釘釘的一整套資料同步方案,他們主要是由服務端來保證的,背後有一個穩定的長連接配接保證,大緻流程如下:
閑魚的服務端暫時還沒有這種能力,原因詳見4.5的服務端存儲模型。是以閑魚這邊隻能從用戶端來控制資料同步的邏輯,資料同步的方式包括:拉取會話、拉取消息、推送消息等。因為涉及到的場景比較複雜,之前有個場景就是推送會觸發增量同步,如果推送過多的話,會同時觸發多次網絡請求,為了解決這個問題,我們也做了相關的推拉隊列隔離。
用戶端控制的政策就是如果在拉取的話,會先将push過來的消息加到緩存隊列裡面,等拉取的結果回來,會再跟本地緩存的邏輯做合并,這樣就可以避免多次網絡請求的問題。之前同僚已經寫了一篇關于推拉流控制的邏輯,
《如何有效縮短閑魚消息處理時長》,這裡也不過多贅述了。
4.4 用戶端模型
用戶端在資料組織形式上,主要分2中:會話和消息,會話又分為虛拟節點、會話節點和檔案夾節點。
在用戶端會建構上圖一樣的樹,這棵樹主要儲存的是會話顯示的相關資訊,比如未讀數、紅點以及最新消息摘要,子節點更新,會順帶更新到父節點,建構樹的過程也是已讀和未讀數更新的過程。其中比較複雜的場景是閑魚情報社,這個其實是一個檔案夾節點,它包含了很多個子的會話,這就決定了他的消息排序、紅點計數以及消息摘要的更新邏輯會更複雜,服務端告知用戶端子會話的清單,然後用戶端再去拼接這些資料模型。
4.5 服務端存儲模型
在4.3中大概講了用戶端的請求邏輯,曆史消息會分為增量和全量域同步。這個域其實是服務端的一層概念,本質上就是使用者消息的一層緩存,消息過來之後會暫存在緩存中,加速消息讀取。但是這個設計也存在一個缺陷,就是域環是有長度的,最多儲存256條,當使用者的消息數多于256條,隻能從資料庫中讀取。
關于服務端的存儲方式,我們也調研過釘釘的方案,是寫擴散,優點就是可以很好地對每位使用者的消息做定制化,比如釘的邏輯,缺點就是存儲量很很大。閑魚的這套解決方案,應該是介于讀擴散和寫擴散之間的一種解決方案。這個設計方式不僅使用戶端邏輯複雜,服務端的資料讀取速度也會比較慢,後續這塊也可以做優化。
5. 我們的解法 - 品質監控
在做用戶端和服務端的全鍊路改造的同時,我們也對消息線上的行為做了監控和排查的邏輯。
5.1 全鍊路排查
全鍊路排查是基于使用者的實時行為日志,用戶端的埋點通過集團實時處理引擎Flink,将資料清洗到SLS裡面,使用者的行為包括了消息引擎對消息的處理、使用者的點選/通路頁面的行為、以及使用者的網絡請求。服務端測會有一些長連接配接推送以及重試的日志,也會清洗到SLS,這樣就組成了從服務端到用戶端全鍊路的排查的方案,詳情請參考
《消息品質平台系列文章|全鍊路排查篇》。
5.2 對賬系統
當然為了驗證消息的準确性,我們還做了對賬系統。
在使用者離開會話的時候,我們會統計目前會話一定數量的消息,生成一個md5的校驗碼,上報到服務端。服務端拿到這個校驗碼之後再判定是否消息是正确的,經過抽樣資料驗證,消息的準确性基本都在99.99%。
6 核心資料名額
我們在統計消息的關鍵名額的時候,遇到點問題,之前我們是用使用者埋點來統計的,發現會有3%~5%的資料差;是以後來我們采用抽樣實時上報的資料來計算資料名額。
消息到達率=用戶端實際收到的消息量/用戶端應該收到的消息量
用戶端實際收到的消息的定義為消息落庫才算是
該名額不區分離線線上,取使用者當日最後一次更新裝置時間,理論上當天且在此時間之前下發的消息都應該收到。
最新版本的到達率已經基本達到99.9%,從輿情上來看,回報丢消息的也确實少了很多。
7. 未來規劃
整體看來,經過一年的治理,閑魚的消息在慢慢的變好,但還是存在一些待優化的方面:
- 現在消息的安全性不足,容易被黑産利用,借助消息發送一些違規的内容。
- 消息的擴充性較弱,增加一些卡片或者能力就要發版,缺少了動态化和擴充的能力。
- 現在底層協定比較難擴充,後續還是要規範一下協定。
- 從業務角度看,消息應該是一個橫向支撐的工具性或者平台型的産品,規劃可以快速對接二方和三方的快速對接。
在2021年,我們會持續關注消息相關的使用者輿情,希望閑魚消息能幫助閑魚使用者更好的完成二手交易。