機器學習算法
廣泛地說,有三種類型的機器學習算法。
1.監督學習
這個算法由一個目标/結果變量(或因變量)組成,這個變量可以從一組給定的預測變量(獨立變量)中預測出來。 使用這些變量,我們生成一個将輸入映射到所需輸出的函數。 訓練過程一直持續到模型達到訓練資料所需的準确度。 監督學習的例子:回歸,決策樹,随機森林,KNN,邏輯回歸等。
2.無監督學習
在這個算法中,我們沒有任何目标或結果變量來預測/估計。 用于不同群體的群體聚類,廣泛用于不同群體的消費者細分進行具體幹預。 無監督學習的例子:Apriori算法,K-means。
3.強化學習:
使用這種算法,機器被訓練做出特定的決定。 它是這樣工作的:機器暴露在一個環境中,它使用反複試驗不斷地訓練自己。 這台機器從過去的經驗中學習,并試圖捕捉最好的知識,做出準确的業務決策。 強化學習執行個體:馬爾可夫決策過程
- 這裡是常用的機器學習算法清單。 這些算法可以應用于幾乎所有的資料問題:
線性回歸
Logistic回歸
決策樹
SVM
樸素貝葉斯
KNN
K均值
随機森林
次元降低算法
梯度提升算法
GBM
XGBoost
LightGBM
CatBoost
1.線性回歸
它用于根據連續變量估計實際值(房屋成本,通話次數,總銷售額等)。在這裡,我們通過拟合最佳線來建立獨立和因變量之間的關系。該最佳拟合線被稱為回歸線,并由線性方程Y = a * X + b表示。
了解線性回歸的最好方法是重溫童年的這種體驗。讓我們說,你問一個五年級的孩子,通過增加體重的順序來安排班上的人,而不要問他們的重量!你覺得孩子會做什麼?他/她可能會檢視(視覺分析)人的身高和身材,并使用這些可見參數的組合進行排列。這是現實生活中的線性回歸!實際上,孩子已經找到了身高,身材與體重之間的關系,看起來像上面的方程式。
在這個等式中:
Y因變量
一個 - 坡度
X - 自變量
b - 攔截
這些系數a和b是基于最小化資料點與回歸線之間的距離的平方和的總和而得出的。
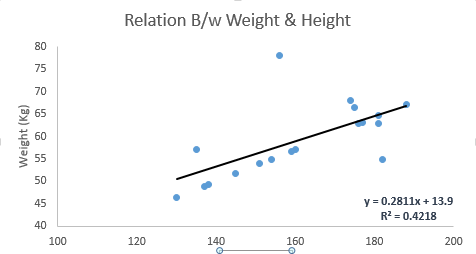
看下面的例子。這裡我們已經确定了具有線性方程y = 0.2811x + 13.9的最佳拟合線。現在使用這個等式,我們可以找到重量,知道一個人的身高。
R代碼:
#Load Train and Test datasets
#Identify feature and response variable(s) and values must be numeric and numpy arrays
x_train <- input_variables_values_training_datasets
y_train <- target_variables_values_training_datasets
x_test <- input_variables_values_test_datasets
x <- cbind(x_train,y_train)
# Train the model using the training sets and check score
linear <- lm(y_train ~ ., data = x)
summary(linear)
#Predict Output
predicted= predict(linear,x_test)
python:
#Import Library
#Import other necessary libraries like pandas, numpy...
from sklearn import linear_model
#Load Train and Test datasets
#Identify feature and response variable(s) and values must be numeric and numpy arrays
x_train=input_variables_values_training_datasets
y_train=target_variables_values_training_datasets
x_test=input_variables_values_test_datasets
# Create linear regression object
linear = linear_model.LinearRegression()
# Train the model using the training sets and check score
linear.fit(x_train, y_train)
linear.score(x_train, y_train)
#Equation coefficient and Intercept
print('Coefficient: \n', linear.coef_)
print('Intercept: \n', linear.intercept_)
#Predict Output
predicted= linear.predict(x_test)
![筆試面試題目:滑動視窗(二)[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)