講了幾天的資料庫系列的文章,大家一定看煩了,其實還沒講完。。。(以下省略一萬字)。
今天我們換換口味,來寫redis方面的内容,談談熱key問題如何解決。
其實熱key問題說來也很簡單,就是瞬間有幾十萬的請求去通路redis上某個固定的key,進而壓垮緩存服務的情情況。
其實生活中也是有不少這樣的例子。比如XX明星結婚。那麼關于XX明星的Key就會瞬間增大,就會出現熱資料問題。
<code>ps:</code>hot key和big key問題,大家一定要有所了解。
本文預計分為如下幾個部分
熱key問題
如何發現
業内方案
上面提到,所謂熱key問題就是,突然有幾十萬的請求去通路redis上的某個特定key。那麼,這樣會造成流量過于集中,達到實體網卡上限,進而導緻這台redis的伺服器當機。
那接下來這個key的請求,就會直接怼到你的資料庫上,導緻你的服務不可用。
方法一:憑借業務經驗,進行預估哪些是熱key
其實這個方法還是挺有可行性的。比如某商品在做秒殺,那這個商品的key就可以判斷出是熱key。缺點很明顯,并非所有業務都能預估出哪些key是熱key。
方法二:在用戶端進行收集
這個方式就是在操作redis之前,加入一行代碼進行資料統計。那麼這個資料統計的方式有很多種,也可以是給外部的通訊系統發送一個通知資訊。缺點就是對用戶端代碼造成入侵。
方法三:在Proxy層做收集
有些叢集架構是下面這樣的,Proxy可以是Twemproxy,是統一的入口。可以在Proxy層做收集上報,但是缺點很明顯,并非所有的redis叢集架構都有proxy。
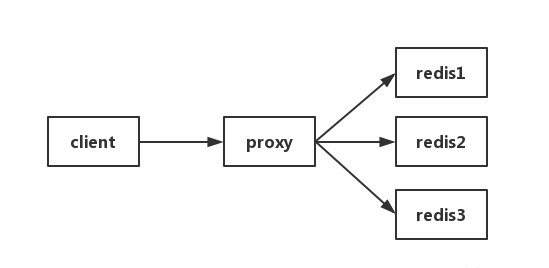
方法四:用redis自帶指令
(1)monitor指令,該指令可以實時抓取出redis伺服器接收到的指令,然後寫代碼統計出熱key是啥。當然,也有現成的分析工具可以給你使用,比如<code>redis-faina</code>。但是該指令在高并發的條件下,有記憶體增暴增的隐患,還會降低redis的性能。
(2)hotkeys參數,redis 4.0.3提供了redis-cli的熱點key發現功能,執行redis-cli時加上–hotkeys選項即可。但是該參數在執行的時候,如果key比較多,執行起來比較慢。
方法五:自己抓包評估
Redis用戶端使用TCP協定與服務端進行互動,通信協定采用的是RESP。自己寫程式監聽端口,按照RESP協定規則解析資料,進行分析。缺點就是開發成本高,維護困難,有丢包可能性。
以上五種方案,各有優缺點。根據自己業務場景進行抉擇即可。那麼發現熱key後,如何解決呢?
目前業内的方案有兩種
(1)利用二級緩存
比如利用<code>ehcache</code>,或者一個<code>HashMap</code>都可以。在你發現熱key以後,把熱key加載到系統的JVM中。
針對這種熱key請求,會直接從jvm中取,而不會走到redis層。
假設此時有十萬個針對同一個key的請求過來,如果沒有本地緩存,這十萬個請求就直接怼到同一台redis上了。
現在假設,你的應用層有50台機器,OK,你也有jvm緩存了。這十萬個請求平均分散開來,每個機器有2000個請求,會從JVM中取到value值,然後傳回資料。避免了十萬個請求怼到同一台redis上的情形。
(2)備份熱key
這個方案也很簡單。不要讓key走到同一台redis上不就行了。我們把這個key,在多個redis上都存一份不就好了。接下來,有熱key請求進來的時候,我們就在有備份的redis上随機選取一台,進行通路取值,傳回資料。
假設redis的叢集數量為N,步驟如下圖所示

注:不一定是2N,你想取3N,4N都可以,看要求。
僞代碼如下
OK,其實看完上面的内容,大家可能會有一個疑問。
煙哥,有辦法在項目運作過程中,自動發現熱key,然後程式自動處理麼?
嗯,好問題,那我們來講講業内怎麼做的。其實隻有兩步
(1)監控熱key
(2)通知系統做處理
正巧,前幾天有贊出了一篇《有贊透明多級緩存解決方案(TMC)》,裡頭也有提到熱點key問題,我們剛好借此說明
在監控熱key方面,有贊用的是方式二:在用戶端進行收集。
在《有贊透明多級緩存解決方案(TMC)》中有一句話提到
TMC 對原生jedis包的JedisPool和Jedis類做了改造,在JedisPool初始化過程中內建TMC“熱點發現”+“本地緩存”功能Hermes-SDK包的初始化邏輯。
也就說人家改寫了jedis原生的jar包,加入了Hermes-SDK包。
那Hermes-SDK包用來幹嘛?
OK,就是做熱點發現和本地緩存。
從監控的角度看,該包對于Jedis-Client的每次key值通路請求,Hermes-SDK 都會通過其通信子產品将key通路事件異步上報給Hermes服務端叢集,以便其根據上報資料進行“熱點探測”。
當然,這隻是其中一種方式,有的公司在監控方面用的是方式五:自己抓包評估。
具體是這麼做的,先利用flink搭建一套流式計算系統。然後自己寫一個抓包程式抓redis監聽端口的資料,抓到資料後往kafka裡丢。
接下來,流式計算系統消費kafka裡的資料,進行資料統計即可,也能達到監控熱key的目的。
在這個角度,有贊用的是上面的解決方案一:利用二級緩存進行處理。
有贊在監控到熱key後,Hermes服務端叢集會通過各種手段通知各業務系統裡的Hermes-SDK,告訴他們:"老弟,這個key是熱key,記得做本地緩存。"
于是Hermes-SDK就會将該key緩存在本地,對于後面的請求。Hermes-SDK發現這個是一個熱key,直接從本地中拿,而不會去通路叢集。
除了這種通知方式以外。我們也可以這麼做,比如你的流式計算系統監控到熱key了,往zookeeper裡頭的某個節點裡寫。然後你的業務系統監聽該節點,發現節點資料變化了,就代表發現熱key。最後往本地緩存裡寫,也是可以的。
通知方式各種各樣,大家可以自由發揮。本文隻是提供一個思路。
希望通過本文,大家明白如何處理生産上遇到的熱key問題。
作者:孤獨煙
出處: http://rjzheng.cnblogs.com/
本文版權歸作者和部落格園共有,歡迎轉載,但未經作者同意必須保留此段聲明,且在文章頁面明顯位置給出原文連接配接,否則保留追究法律責任的權利。如果覺得還有幫助的話,可以點一下右下角的【推薦】。